![[論文] SIGMOD/PODS 2024「Amazon Redshift における自動化された多次元データレイアウト」](https://devio2024-media.developers.io/image/upload/f_auto,q_auto,w_3840/v1728398603/user-gen-eyecatch/jdrqzkcsenki2njbj8sk.jpg)
[論文] SIGMOD/PODS 2024「Amazon Redshift における自動化された多次元データレイアウト」
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
AWS事業本部コンサルティング部の石川です。昨年のre:Invent2023 で発表された クエリのパフォーマンスを最適化する多次元データレイアウトを発表 (プレビュー)について、データベース研究分野における最も重要な国際会議の1つである SIGMOD/PODS 2024 で、論文が発表されました。まだプレビュー中の新機能について論文をベースに解説します。
SIGMOD’24について、Ippokratis PandisさんもXに投稿しています!
Automated multidimensional data layouts in Amazon Redshift
分析データシステムでは、データのスキャンとフィルタリングのパフォーマンスを向上させるためにデータレイアウト技術が使用されています。この論文では、同じようなフィルター条件が頻繁に使用されるデータベース操作に対して既存の技術を上回る新しいデータレイアウト技術「多次元データレイアウト(MDDL)」を紹介しています。
MDDLは、述語に基づいてソートし、最適な述語を自動的に学習する、商用製品における初のデータレイアウト技術とされています。
ABSTRACT
分析データシステムでは、データのスキャンとフィルタリングのパフォーマンスを向上させるために様々なデータレイアウト技術が使用されます。本論文では、新しいデータレイアウト技術である多次元データレイアウト(MDDL)を紹介しています。MDDLは、頻繁に使用されるスキャンフィルターを含むクエリワークロードに対して、既存のデータレイアウト技術よりも優れたパフォーマンスを発揮します。
従来のアプローチがカラムに基づいてテーブルをソートするのに対し、MDDLは述語の集合に基づいてソートを行います。これにより、ユーザーのワークロードに対してより精密なカスタマイズが可能になります。さらに、過去のワークロードから収集された情報に基づいて、各テーブルに最適なMDDLを自動的に学習するアルゴリズムも導入されています。
Amazon Redshiftに実装されたMDDLは、内部データセットとワークロードのベンチマークで、従来のカラムベースのデータレイアウト技術と比較して、最大85%のワークロード実行時間の削減を達成しました。これは、クエリパフォーマンスの大幅な向上を示しています。
1 INTRODUCTION
Amazon Redshiftの新機能「多次元データレイアウト(MDDL)」について説明します。
MDDLは、分析データシステムのパフォーマンスを向上させる新しいデータレイアウト技術です。従来のソートキーによる方法と異なり、MDDLはクエリのフィルター条件に基づいてデータを効率的に分割します。これにより、クエリ実行時に関連するデータブロックのみにアクセスし、不要なブロックをスキップできます。
MDDLの仕組みは、テーブルの行を複数の条件に基づいて0から3の値にマッピングし、その値を新しい列(mddl_col)として追加してソートキーとして使用します。これにより、クエリのフィルター条件を単純化し、データアクセスを最小限に抑えることができます。
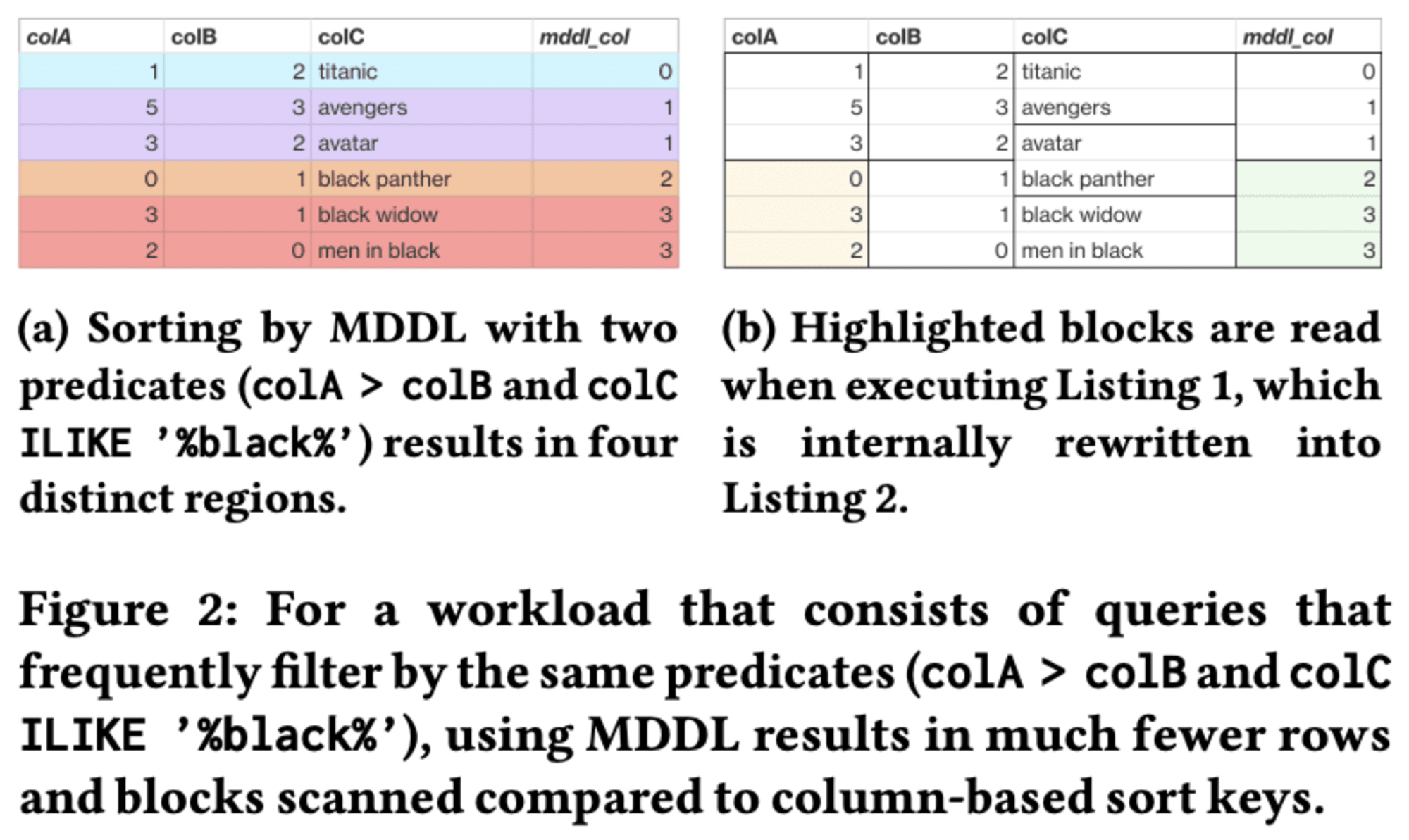
Redshiftに実装されたMDDLは完全に自動化された機能で、ユーザーが明示的にソートキーを選択していない場合に適用されます。内部のベンチマークでは、従来のデータレイアウト手法と比較して、ワークロードの実行時間を最大85%削減し、個々のクエリで最大100倍の高速化を達成しています。
MDDLは、述語に基づいてソートし、最も効果的な述語を自動的に学習する初めての商用データレイアウト技術です。現在パブリックプレビュー段階にあり、近い将来に一般提供される予定です。
2 BACKGROUND
2.1 Data layouts
現代の分析システムでは、テーブルの物理的なデータレイアウトは通常、単一または複数の列に基づいてソートされます。しかし、単一列のソート順序は複数の列でフィルタリングする場合に効果が低く、複数列のソート順序の手動調整は労力がかかり、エラーが発生しやすいです。
Amazon RedshiftやDatabricksは自動的に最適な列ベースのデータレイアウトを選択し、時間とともに進化させる機能を提供していますが、述語ベースのレイアウトはサポートしていません。一方、SnowflakeやOracleは述語に基づくクラスタリングやインデックス作成をサポートしていますが、自動的な述語選択はサポートしていません。
これらに対し、MDDLは自動化された述語ベースのデータレイアウトを提供します。インスタンス最適化データレイアウトは、特定のデータセットやワークロードに高度に特化した複雑なデータレイアウトを自動生成することを目指す技術であり、MDDLはこれらの技術からインスピレーションを得ています。
2.2 Amazon Redshift
Amazon Redshiftは、複数のEC2ノードにまたがるMPP実行エンジンを使用し、データはS3に保存され、高速アクセスのためにEC2ノードのローカルディスクにキャッシュされます。Redshiftは列指向ストレージを採用し、各列のデータを圧縮形式で1MBの固定サイズのデータブロックに格納します。データスキャン時には、列フィルターに基づいて行範囲を特定し、関連するデータブロックのみをスキャンします。Redshift Advisorは、テーブルの物理設計に関する推奨事項を提供し、 Automatic Table Optimization(ATO) がこれらの変更を自動的に適用します。また、Automatic Table Sortは、バックグラウンドでテーブルを徐々にソートし、パフォーマンスを向上させます。これらの自動化機能により、従来のデータベース管理者の作業負担が大幅に軽減されています。
3 MDDL OVERVIEW
MDDL の全体像は、以下のとおりです。
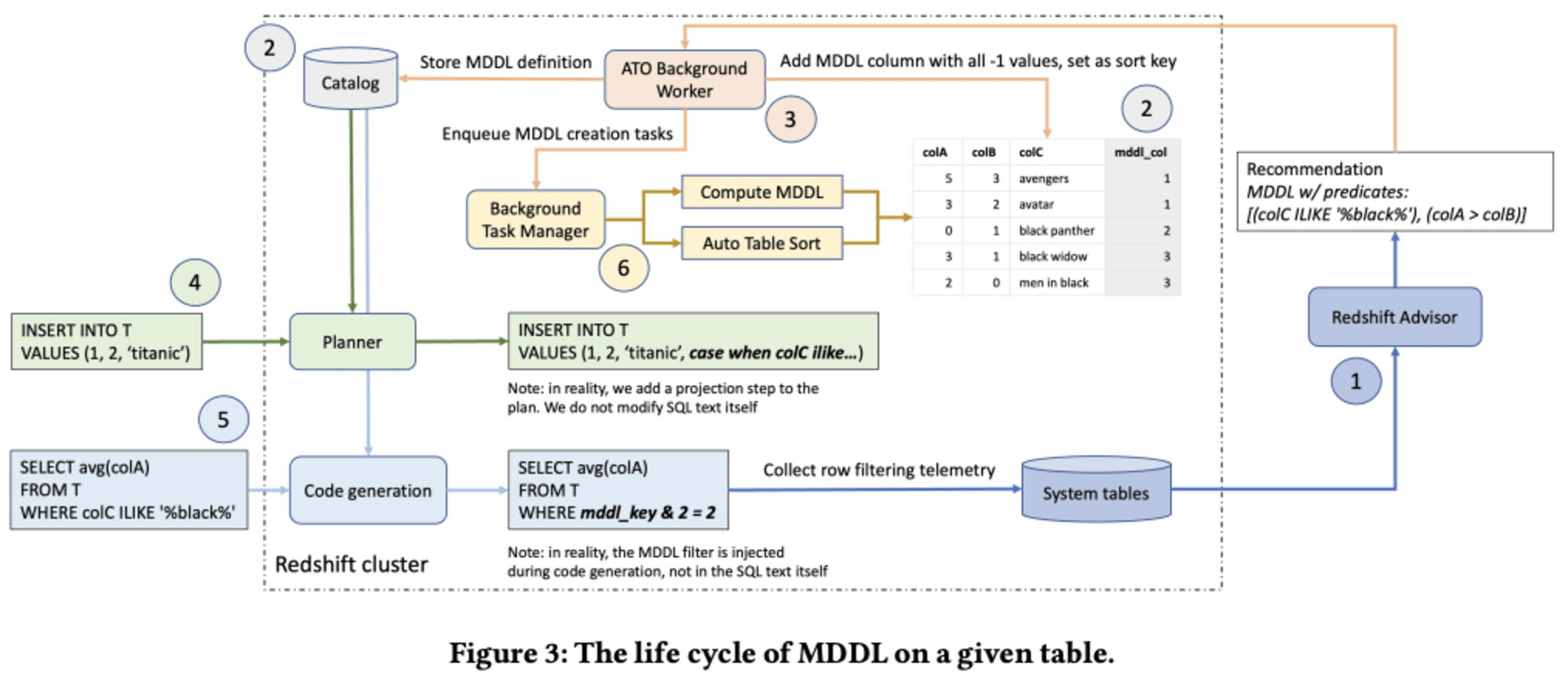
3.1 Design Principles
MDDLの実装において、複数の設計原則に従いました。まず、データ駆動型の設計決定を行うため、フリート全体の分析を実施し、データレイアウトを通じてパフォーマンスを向上させる最も効果的な方法を定量的に決定しました。
フィルター述語が非常に反復的であることを発見し、顧客クラスターの50%以上で、スキャンフィルターの80%以上が完全に一致することがわかりました。そのため、MDDLでは述語の完全一致に焦点を当てることにしました。また、顧客のワークロードへの影響を最小限に抑えるため、MDDLの作成とメンテナンスは可能な限りバックグラウンドタスクに依存しています。さらに、Redshiftの他のコンポーネントとの適切な相互作用を考慮し、既存のコンポーネントの上に構築するよう設計しました。
3.2 Strengths and Limitations
MDDLの強みは、従来のカラムベースのソート技術と比較して、ユーザーのワークロードに高度に特化したデータレイアウトを実現します。頻繁に使用される述語を直接ソートに利用することで、多くのスキャンフィルターでブロックスキップが可能になります。また、MDDLは半構造化データや地理空間データなど、自然な順序がない列でもソートが可能という利点があります。
制限事項として、MDDLは単一テーブル上の述語のみを使用し、結合条件や結合によって派生する条件は使用しないため、大規模テーブルのスキャンが小規模テーブルの条件に基づくデータレイアウトから恩恵を受けるようなワークロードでは効果が限定的です。また、RANDOM()のようなミュータブルな関数を使用する非決定的な述語は使用できません。
4 MDDL LIFE CYCLE
4.1 Storage
MDDLを使用するテーブルは、追加のカラムとカタログ内のメタデータという2つの場所でストレージのオーバーヘッドが発生します。MDDLカラムは、ユーザーには隠されており、各行の値はビットマップとして解釈されます。各ビット位置は述語と関連付けられ、その値は対応する行が述語を満たすかどうかを表します。
MDDLカラムの最上位ビットは、他のすべてのビットが正しく設定されている場合にのみ0に設定されます。負のMDDL値は、正しい値がまだ計算されていないことを示す一時的な値です。
カタログには、MDDLの定義が格納されており、述語の定義とそれに関連付けられたビット位置が含まれます。時間の経過とともに、一部の述語が無効になる可能性がありますが、Redshiftはそのような場合を検出し、自動的に述語を無効化します。
MDDLは作成後に述語を追加できませんが、述語を削除することは可能です。これにより、MDDLの柔軟性と管理が容易になります。
4.2 Usage in Accelerating Scans
MDDLをスキャンに使用する際には、主に2つの方法があります。1つ目はMDDLを使ってブロックをスキップし、スキャンする行数を減らすことです。2つ目は冗長なユーザー述語をスキップして、スキャンする列数を減らすことです。
MDDLはテーブルごとに適用されます。まず、クエリプランナーがクエリを分析し、データの読み取り段階(スキャン)でフィルターします。これにより、早い段階で不要なデータを除外できます。この最適化が行われた後にMDDLロジックが適用されます。Redshiftは自動的にMDDLを適用し、カタログからMDDL述語を読み取り、クエリフィルターの述語と比較して一致するものを見つけます。一致する述語があれば、MDDL列に対する述語を構築します。
MDDLフィルターはビット比較として記述され、効率的に評価されます。ブロックスキップロジックを使用して、不要なブロックの読み取りを避けます。また、SIMD命令を使用した特殊なベクトル化スキャン演算子を使用して、MDDL列に対してMDDLフィルターを効率的に評価します。
さらに、MDDLフィルターが適用された後は、一致した述語を再度適用する必要がなくなります。これにより、それらの述語が参照する列を読み取る必要がなくなり、述語評価のキャッシュとして機能します。MDDL列が完全に計算されていない場合でも、適応的な実行することで部分的な最適化が可能です。
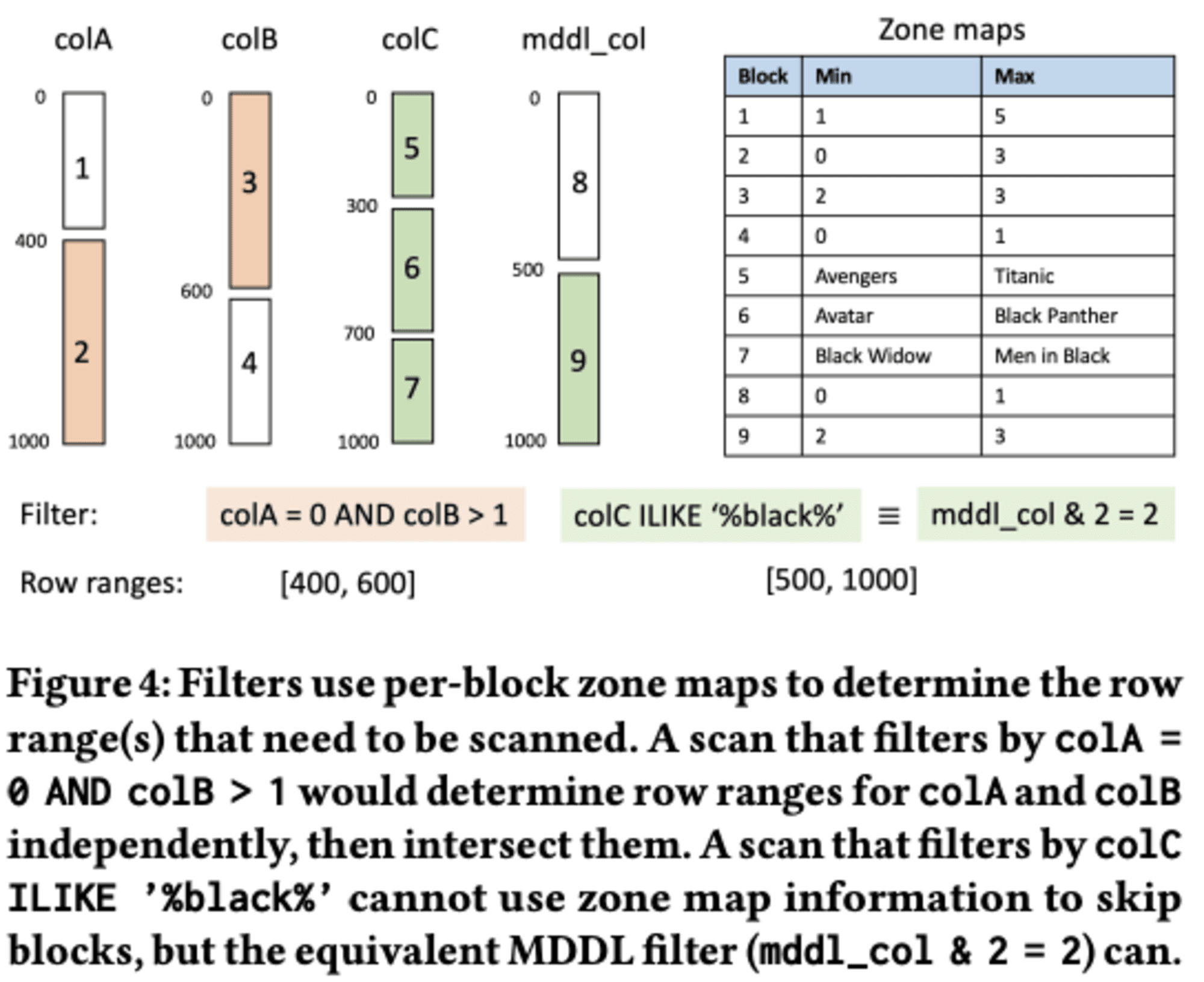
4.3 Creation
MDDLテーブルの作成プロセスは、3つのステージで構成されています。
- 未計算の値を持つMDDL列を作成し、カタログに述語定義を登録する
- MDDL列の値を計算する
- MDDL列でテーブルをソートする
各ステージは、時間がかかる順に並んでいます。各ステージはバックグラウンドタスクとして実行され、ユーザーの作業への影響を最小限に抑えます。このようにステージを分けることで、スケジューリングが容易になり、長時間のタスクによる進捗の損失を防ぎます。さらに、第2ステージが始まった時点でMDDLは既に有用となり、他の述語列の読み取りを回避できるようになります。
4.4 Maintenance Under Changing Data
MDDLの維持管理について、データの変更に伴う2つの側面を説明します。まず、MDDL列の正確な値を維持する必要があります。行が変更されない限り、そのMDDL値も正確なままです。新しく挿入された行のみ、MDDL値を自動的に計算します。これは挿入やCOPYコマンドの書き込み経路で行われ、オーバーヘッドは最小限に抑えられます。
次に、MDDL列に基づいてテーブル全体のソート順を維持する必要があります。Redshiftでは、挿入された行はテーブルの末尾に追加されます。バッチ挿入の場合、メモリ内でソートされてから挿入されるため、各バッチ内でのソート順は保たれます。
しかし、バッチ間のソート順は必ずしも保たれません。そこで、MDDLはRedshiftの既存のメカニズムを利用します。ユーザーが手動でVACUUM SORTを実行するか、Automatic Table Sort (ATS)が自動的にソートします。ATSは背景プロセスとして動作し、ソートが性能を向上させるかどうかを判断し、効果的なタイミングでソートを実行します。
4.5 Retirement
Redshiftでは、データやワークロードの変化により、テーブルに定義されたMDDL(Materialized Dynamic Distributed Layout)が最適でなくなる可能性があります。より適切な述語を持つMDDLや、従来の単一列ソートキーがより効果的になることがあります。ソートキーの変更タイミングを決定するため、Advisorアルゴリズムを使用します。
Advisorは、最後の推奨以降のワークロードに基づいてベネフィットを計算し、代替ソートキーのベネフィットが既存のソートキーの観測されたベネフィットを上回ると判断した場合、自動的に移行を開始します。ただし、ソートキーの頻繁な変更を防ぐため、変更間隔の最小時間を設定しています。
5 AUTOMATIC MDDL SELECTION
Redshift Advisor は、どのテーブルに MDDL を作成するか、および各 MDDL で使用する述語を自動的に決定します。
5.1 Redshift Advisor
Redshift Advisorは、テーブルごとのソートキー推奨します。以前はMDDLの導入前は単一カラムのソートキーに限られていました。この推奨は、ユーザーのワークロードから収集された履歴テレメトリに基づいています。各テーブルスキャンにおいて、Redshiftは各カラムによってフィルタリングされた行数を記録します。Advisorは定期的にこのテレメトリを読み取り、クラスター全体の履歴(または前回の推奨以降)におけるすべてのクエリで各カラムがフィルタリングした総行数を集計します。そして、最も多くの行をフィルタリングしたカラム(最も効果の高いカラム)をソートキーとして推奨します。
Advisorは固定のルールを使用して、推奨をユーザーまたはAutomatic Table Sort (ATS)のバックグラウンドワーカーに提示するかどうかを決定します。例えば、ユーザーが既に手動でテーブルのソートキーを選択している場合や、既存のデータレイアウトが推奨されたソートキーと同程度の行フィルタリングを達成していることをテレメトリが示している場合は、推奨を送信しません。
5.2 MDDL in Redshift Advisor
AdvisorにおけるMulti-Dimensional Data Layouts(MDDL)の導入について、2つの主要な変更が行われました。
まず、テレメトリの収集方法が改善されました。スキャン時に各列によってフィルタリングされた行数を記録するだけでなく、各述語によってフィルタリングされた行数も記録するようになりました。これには、述語を使用してスキップされたブロック内の行数と、スキャンされた行範囲から述語によってフィルタリングされた行数の両方が含まれます。
次に、MDDLの選択方法が確立されました。Advisorは、すべての過去のクエリにわたって各述語によってフィルタリングされた行を集計し、フィルタリングされた行数に基づいて上位n個の述語を選択してMDDLの候補を構築します。この候補MDDLの利点は、すべての述語によってフィルタリングされた総行数です。Advisorは、候補MDDLと候補単一列ソートキー、および既存のソートキー(存在する場合)の全体的な利点を比較し、最も高い利点を持つものを推奨します。
nの値は、各MDDLの列の値に対して同数の行がある場合、同じMDDL値を持つすべての行が1つの1MBデータブロックに収まるという経験則に基づいて選択されます。これは、データレイアウトの主な利点がブロックスキッピングから得られるため、一度行が特定のブロックに割り当てられると、そのブロック内の行をさらに区別することの利点は最小限であるという考えに基づいています。
この手法の利点は、ユーザークエリの実行の副作用として収集されるテレメトリのみに依存し、データサンプルの収集や保存に関連するパフォーマンスのオーバーヘッドを軽減し、顧客データの取り扱いに関連するプライバシーやセキュリティの懸念を回避できることです。
6 EVALUATION
Redshiftの既存のデータレイアウト技術と比較してMDDLの性能を評価しています。内部の3つのワークロードにおいて、MDDLは単一カラムのソートキーを使用した場合と比べて最大10倍、複合およびインターリーブソートキーと比べて最大7倍のパフォーマンス向上を達成しました。また、Redshift全体の顧客データを分析した結果、約25%のテーブルがMDDLの恩恵を受け、上位5%のクラスターではワークロード全体のフィルタリング行数が2倍に増加すると推定されています。これらの結果は、MDDLが既存の技術を大きく上回る効果的なデータレイアウト手法であることを示しています。
6.1 Setup
MDDLは、Redshiftの既存のデータレイアウト技術と比較して、大幅なパフォーマンス向上を実現します。
- 単一列のソートキーを使用する場合と比べて最大10倍、複合およびインターリーブドソートキーと比べて最大7倍のワークロードパフォーマンスを達成します。
- Redshift全体の顧客テーブルの約25%に恩恵をもたらし、上位5%のクラスターでは、ワークロード全体でフィルタリングされる行数を2倍に増加させると推定されています。
これらの結果は、MDDLが既存のデータレイアウト技術を大きく上回る効果的な手法であることを示しています。
6.2 Overall Results
研究者たちは、3つの異なる内部ワークロードを評価し、5つのデータレイアウト設定を比較しました。これらの設定には、元のデータレイアウト、単一列ソートキーを推奨するRedshift Advisor、MDDL(Multi-Dimensional Data Layout)を含むAdvisor、複合ソートキー、インターリーブドソートキーが含まれます。
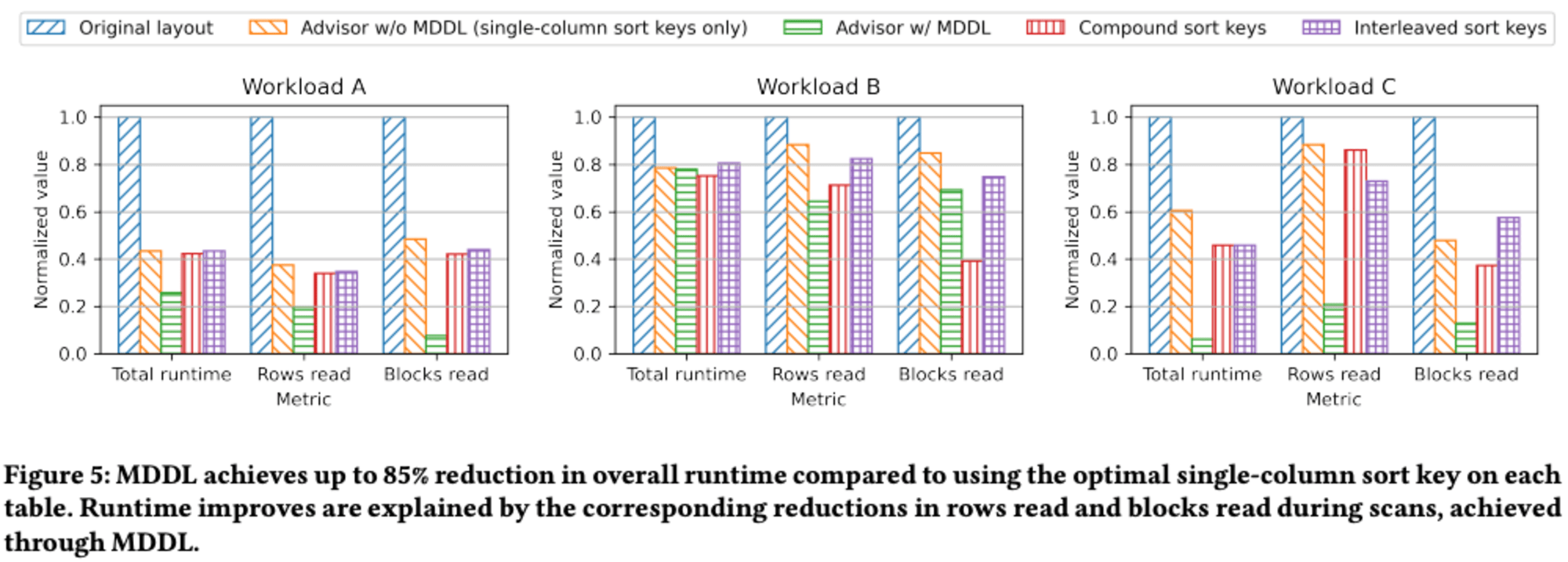
各ワークロードに対して、元のデータレイアウトでクエリを実行し、その後Advisorを使用して新しいソートキーの推奨を生成しました。これらの新しいソートキーを適用し、テーブルを完全にソートした後、ワークロードを再実行してパフォーマンスを測定しました。
研究者たちは、より複雑なインスタンス最適化データレイアウト技術との比較は行っていません。その理由として、これらの技術が実践的に実装困難であることや、プライバシーの懸念を引き起こす可能性があることを挙げています。この研究は、データベースのパフォーマンス向上のための実用的なアプローチを探求しています。
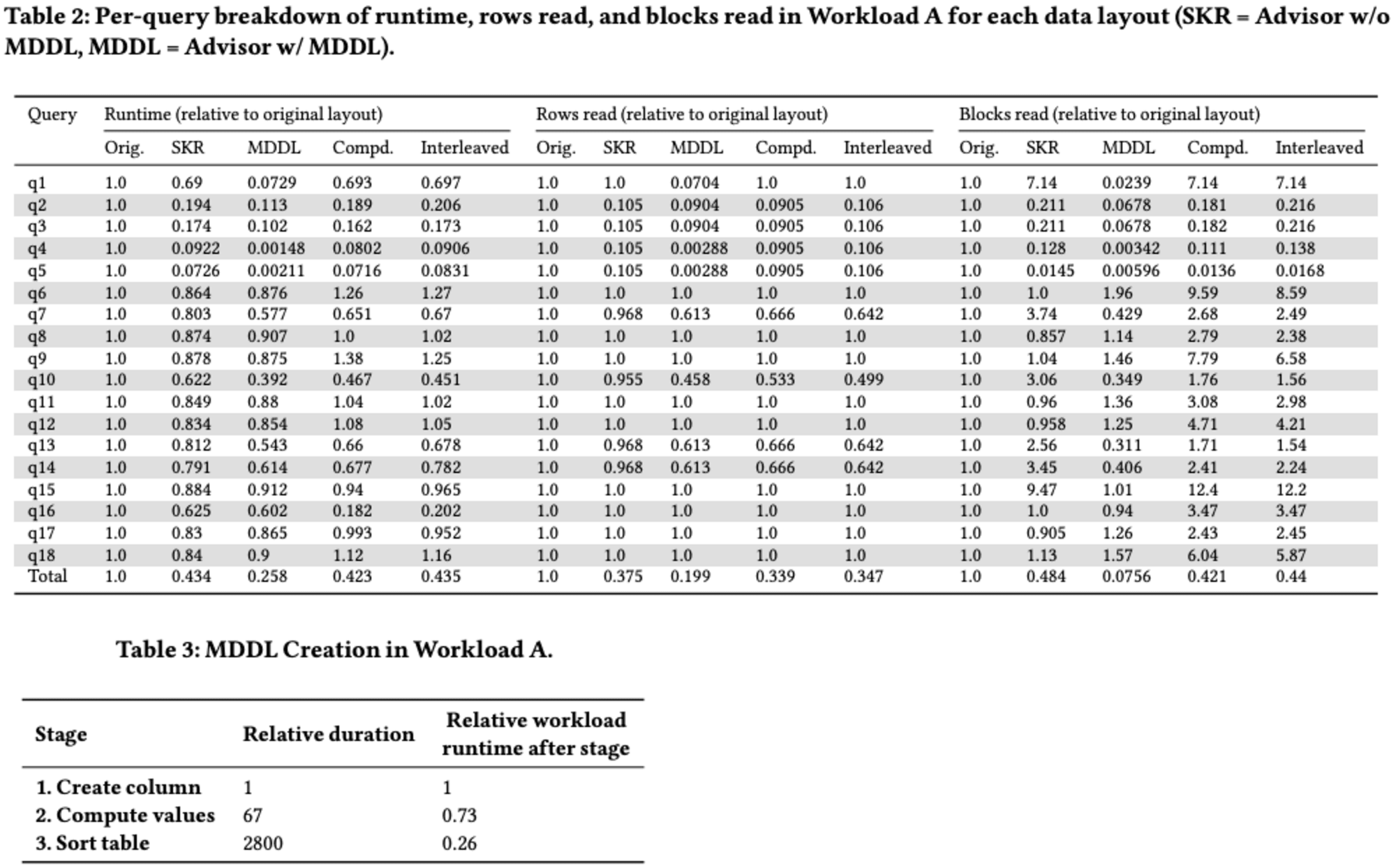
6.3 Deep Dive into Workload A
上図のMDDLのWorkload Aにおける動作について、より詳細な分析を行った結果です。
MDDLは、クエリの特性に応じて異なる効果を発揮します。例えば、Query 1では複雑なフィルター条件を含む集計を行いますが、MDDLはこの条件が頻出する場合に効果的です。該当するデータブロックのみをスキャンすることで、パフォーマンスが向上します。
-- Query 1 is of this form:
SELECT season, sum(metric2) AS "__measure__0",
FROM titles
WHERE lower(subregion) like '%united states%'
GROUP BY 1
ORDER BY 1 asc;
Query 4では複数の条件を組み合わせたフィルタリングを行いますが、MDDLはすべての条件を活用し、必要最小限のデータブロックのみを読み取ることで最高のパフォーマンスを実現します。
-- Query 4 is of this form:
SELECT * FROM titles
WHERE subregion = 'United States'
AND date >= '2007-01-01' AND date <= '2017-02-28'
AND season_desc IS NULL
LIMIT 1
MDDLの作成プロセス(Table 3)は3段階に分かれており、各段階でワークロードの実行時間が変化します。特筆すべきは、2段階目の列値計算後から既にパフォーマンスが向上し始める点です。これにより、テーブルの完全なソートを待たずにMDDLの恩恵を受けられます。最終的に3段階目が完了すると、MDDLは最大の効果を発揮し、大幅な実行時間の短縮を実現します。
6.4 Fleet Projections
Redshiftでは、全ての顧客とクラスターから匿名化された利用データを収集し、MDDLの性能を予測しています。この分析によると、行数でランク付けされた上位1万テーブルのうち約25%が、単一列のソートキーよりもMDDLを使用することで、より多くの行をフィルタリングできることが分かりました。これらのテーブルの90パーセンタイルでは、MDDLを使用することで3倍多くの行をフィルタリングできると予測されています。
クラスターレベルの分析では、過去1日間に少なくとも100のフィルタリングスキャンを持つクラスターを対象に、MDDLと単一列ソートキーの性能を比較しました。90パーセンタイルのクラスターでは、全てのスキャンにおいて約1.5倍多くの行をフィルタリング可能、95パーセンタイルのクラスターでは2倍多くの行をフィルタリングできると予測されています。
これらの予測では、MDDLは最適な単一列ソートキーよりも性能が優れるテーブルにのみ適用され、それ以外のテーブルでは最適な単一列ソートキーが使用されます。このアプローチにより、MDDLの導入が性能低下を引き起こすことはなく、常に少なくとも現状と同等以上の性能が期待できます。
7 DISCUSSION
このセクションでは、設計上の考察、MDDLとRedshift の他のコンポーネントとの相互作用、および今後の作業の方向性について説明します。
7.1 Design Decisions
Redshiftでは、MDDLをテーブルの実体化された列として実装し、既存の列メタデータ(ブロックごとの最小/最大値)を活用しています。この方法には、仮想列を使用する方法や新しいインデックス構造を導入する方法などの代替案がありました。
仮想列の使用はストレージ空間を節約できますが、クラウドベースのシステムであるRedshiftではストレージは通常ボトルネックにならず、また値の再計算が必要になるというデメリットがあることから採用されませんでした。
新しいインデックス構造の導入は、追加のメンテナンスオーバーヘッドが発生する可能性があり、既存のゾーンマップで十分なブロックスキップ機能が提供されていることから採用されませんでした。
7.2 Interactions with Other Components MDDL complements existing performance-enhancing features in Redshift.
MDDLは、Redshiftのデータ管理において新たな選択肢を提供する技術です。従来のカラムベースのソートキーと比較して、MDDLは頻繁に繰り返されるスキャンフィルターに特化しています。結果キャッシュとは相補的な関係にあり、データ変更が頻繁な環境でも効果を発揮します。
また、自動マテリアライズドビューとも共存可能で、ユーザーテーブルだけでなくマテリアライズドビュー自体にも適用できます。MDDLの有用性は、Advisorによって継続的に評価され、必要に応じて最適化されます。このように、MDDLはRedshiftのパフォーマンス向上に貢献する柔軟で効果的なツールとして位置づけられています。
7.3 Future Directions
MDDLという新しいデータレイアウト技術の将来的な改善点について議論します。
まず、厳密な一致ではなく、地理空間データのような交差や包含関係に基づくマッチングへの拡張が提案されています。これにより、より柔軟なクエリ処理が可能になりますが、複雑な述語や関数を含む場合、マッチングロジックが著しく困難になる可能性があります。
次に、マテリアライズドビューの選択とMDDLの統合について言及しています。両者は過去のワークロードから繰り返しのクエリパターンを識別し、将来の類似クエリを高速化するという共通の目標を持っています。しかし、クエリ全体の高速化と走査のみの高速化、データ変更に対する柔軟性、メンテナンスコストなど、それぞれ異なるトレードオフがあります。これらのトレードオフを分析し、選択アルゴリズムを組み合わせることで、より効果的な最適化が可能になると考えられています。
最後に、過去の研究では、データレイアウトとマテリアライズドビューの統合選択が提案されていましたが、現代のクラウド環境では、ストレージ容量よりもメンテナンスのオーバーヘッドが制約となっているため、新たなアプローチが必要であることが指摘されています。これらの改善点を追求することで、より効率的なデータベース管理システムの実現が期待されます。
8 CONCLUSION
この論文では、 Amazon Redshiftの新機能「多次元データレイアウト(MDDL)」 を紹介しました。MDDLは、従来の単一列ソートキーや複合ソートキー、インターリーブドソートキーよりも、頻繁に繰り返されるスキャンフィルターを使用するワークロードで優れたパフォーマンスを発揮します。
Redshiftはユーザーの過去のワークロードを学習し、各テーブルに最適なMDDLを自動的に実装、維持、使用します。顧客のワークロードから得たベンチマークでは、MDDLが従来のレイアウト技術と比較して、最大10倍のパフォーマンス向上を示しています。Redshiftのテーブルの約25%がMDDLの恩恵を受けると予測されています。
※ 多次元データレイアウト(MDDL): 執筆時点では、プレビューです。
最後に
re:Invent2023のキーノートで発表され、以前から紹介したかった論文、Automated multidimensional data layouts in Amazon Redshift です。
現在のAmazon Redshiftでは、テーブル作成時にSORTKEYをAUTOに指定すると、Redshiftがワークロードパターンを観察し、最適なソートキーを自動的に選択します。この機能は、自動テーブル最適化(Automatic Table Optimization)の一部です。クエリとテーブルの利用状況を継続的に監視し、パフォーマンスが向上すると判断した場合、自動的にSORTKEYのカラムや種類を選択して、変更を適用、新しいソートキーに従いデータを並び替えます。
今回紹介するMDDL(multidimensional data layouts)は、機械学習を用いて述語(クエリのフィルター条件)に基づいてデータを効率的に分割します。これにより、クエリ実行時に関連するデータブロックのみにアクセスし、不要なブロックをスキップすることでパフォーマンスを改善します。
MDDLは、新たにテーブルに MDDL列(mddl_col) という隠しカラムを作成し、条件に一致した分類の番号(正確にはビットマップ)を設定します。MDDL列は数値であるため、通常のソートキー(COMPOUND SORTKEY)と同様にデータを順に並び替えることができます。Redshiftは、ソートキーを自動設定するか、MDDL列に設定した値でソートするか、どちらがワークロードに適しているかを推論して選択します。
この機能は既存の機能と競合するものではなく、ワークロードに最適なテーブルレイアウトを推論して自動的に適用されます。利用者はSORTKEYをAUTOに設定するだけで、Redshiftが推論してソートキーを最適化します。
合わせて読みたい










